Z-Image Turbo: Redefining Efficient AI Image Generation
Discover Z-Image Turbo, a 6-billion-parameter foundation model that transforms text into stunning photorealistic images. Developed by Alibaba's Tongyi-MAI team, this model brings professional-grade image synthesis to standard hardware, supporting both English and Chinese with remarkable accuracy and speed.
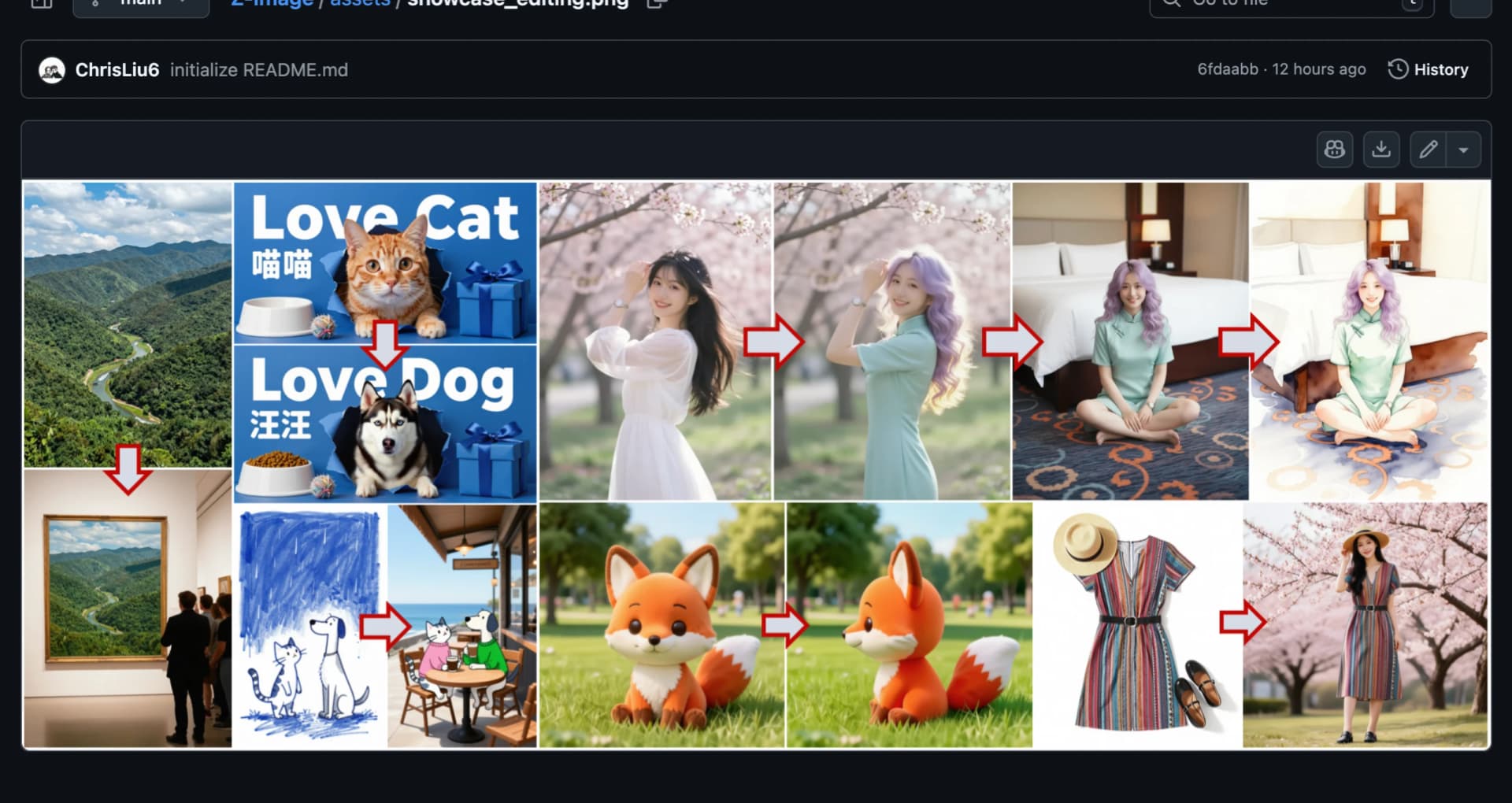

Efficiency Meets Excellence in Image Synthesis
Z-Image Turbo challenges the conventional wisdom that bigger is always better in AI models. Through intelligent architectural design and sophisticated training methodologies, this 6-billion-parameter model delivers image quality that rivals systems with 60+ billion parameters. The model employs a single-stream diffusion transformer architecture, carefully optimized to maximize computational efficiency while preserving the nuanced understanding needed for complex image generation tasks. This approach represents a fundamental shift in how we think about model design—prioritizing smart engineering over brute-force scaling. The result is a system that democratizes access to professional image generation capabilities, making them available to individual creators, small studios, academic researchers, and developers working with limited computational budgets. By requiring less than 16GB of VRAM, Z-Image Turbo runs comfortably on consumer graphics cards that cost a fraction of enterprise-grade hardware. This accessibility doesn't come at the expense of capability; the model maintains sophisticated understanding of composition, lighting, texture, and style across diverse generation tasks.
- Operates efficiently on consumer GPUs with under 16GB VRAM
- Produces high-quality images in only 8 inference steps
- Native bilingual support for Chinese and English text
- Single-stream transformer architecture for optimal performance
- Publicly available model weights under Apache-2.0 license
- Comprehensive documentation and implementation examples
- Active development with regular updates and improvements
- Compatible with popular inference frameworks and pipelines

Photorealistic Quality Across Diverse Scenarios
The photorealistic capabilities of Z-Image Turbo extend far beyond simple object generation. The model demonstrates sophisticated understanding of physical properties, material characteristics, lighting conditions, and spatial relationships. When generating portraits, it captures subtle skin textures, natural hair patterns, and authentic facial expressions. For landscape scenes, it renders atmospheric perspective, accurate shadows, and realistic environmental details. The model's training on diverse, high-quality datasets enables it to handle complex prompts involving multiple subjects, specific artistic styles, particular lighting conditions, and detailed scene compositions. Its bilingual nature isn't merely about language translation—the model genuinely understands cultural contexts and aesthetic conventions associated with both Chinese and English descriptions. This makes it particularly valuable for international projects requiring culturally appropriate imagery. The consistency of output quality across the reduced 8-step generation process is remarkable; early steps establish composition and major elements, while later steps refine details and enhance realism. This efficiency means users can iterate rapidly, exploring multiple variations of a concept in the time traditional models would take to generate a single image.
- Accurate rendering of complex materials and textures
- Sophisticated understanding of lighting and shadow physics
- Strong compositional sense for balanced, aesthetic outputs
- Precise interpretation of detailed multi-element prompts
- Cultural awareness in bilingual content generation
- Consistent quality across reduced inference steps
- Natural handling of human figures and facial features
- Realistic environmental and atmospheric effects
- Proper spatial relationships and perspective rendering

Designed for Real-World Applications
Z-Image Turbo was developed with practical deployment in mind, addressing the real constraints faced by creators and developers. The model's architecture supports efficient batching for processing multiple requests, making it suitable for production environments serving numerous users. Its reduced memory footprint allows deployment on standard cloud instances without requiring specialized hardware configurations. The 8-step generation process significantly reduces latency, enabling near-real-time applications that would be impractical with slower models. Integration is straightforward thanks to compatibility with established frameworks and clear documentation covering common use cases. The model supports various aspect ratios and resolutions, adapting to different output requirements without retraining. For developers building applications, the predictable resource usage and consistent performance characteristics simplify capacity planning and cost estimation. The open-source nature encourages experimentation and customization—teams can fine-tune the model for specific domains, adjust generation parameters for their use cases, or integrate it into larger systems. Beyond individual use, Z-Image Turbo serves educational purposes, allowing students and researchers to study modern diffusion models without prohibitive hardware costs. Its efficiency also makes it environmentally responsible, consuming significantly less energy per generated image compared to larger alternatives.
- Production-ready architecture with efficient batching support
- Straightforward integration with popular ML frameworks
- Flexible resolution and aspect ratio handling
- Predictable resource usage for reliable deployment
- Extensive documentation covering implementation patterns
- Community-contributed examples and use cases
- Regular model updates with backward compatibility
- Support for fine-tuning on domain-specific data
- Energy-efficient operation reducing environmental impact
- Suitable for both research and commercial applications
Deep Dive into Z-Image Technology
Explore the technical innovations and practical applications that make Z-Image Turbo a powerful tool for creators and developers.
Technical Architecture and Innovation
The technical foundation of Z-Image Turbo represents careful engineering decisions at every level. The single-stream diffusion transformer architecture processes both text and image information through a unified pathway, eliminating redundancy present in multi-stream designs. This architectural choice reduces parameter count while maintaining representational capacity. The attention mechanisms have been optimized to focus computational resources on the most informative features, improving both speed and quality. The model employs sophisticated normalization techniques that stabilize training and improve generalization to diverse prompts. The text encoder has been specifically enhanced to handle bilingual inputs, with shared representations that capture semantic similarities across languages while respecting linguistic differences. The denoising process has been carefully calibrated to maximize quality at reduced step counts—each step is more effective than in traditional models, achieving comparable denoising with fewer iterations. The training process itself involved multiple stages: initial pretraining on large-scale image-text pairs, followed by quality-focused fine-tuning, and finally distillation from larger teacher models to compress knowledge into the efficient student architecture. This multi-stage approach ensures the model captures both broad perceptual understanding and refined quality standards.
Performance Characteristics and Benchmarks
Rigorous evaluation demonstrates that Z-Image Turbo achieves competitive performance across standard benchmarks for image generation quality. In human preference studies, images generated by Z-Image Turbo frequently match or exceed those from models with 10x more parameters. The model shows particular strength in prompt adherence—accurately capturing specified objects, attributes, relationships, and styles. For text rendering within images, a notoriously challenging task, Z-Image Turbo demonstrates high accuracy for both Latin and Chinese characters, maintaining legibility even in complex scenes. Generation speed benchmarks show the 8-step process completing in seconds on consumer hardware, compared to minutes for traditional 50-step approaches. Memory efficiency tests confirm stable operation within 16GB VRAM constraints even at higher resolutions. The model maintains consistent quality across different random seeds, producing reliable results rather than highly variable outputs. Comparative studies against commercial APIs show Z-Image Turbo delivering similar aesthetic quality while offering the advantages of local deployment, data privacy, and zero per-image costs. These performance characteristics make the model practical for applications ranging from rapid prototyping to production content generation.
Practical Applications and Use Cases
The unique combination of quality, efficiency, and accessibility opens Z-Image Turbo to diverse applications. Content creators use it for generating marketing materials, social media graphics, and conceptual imagery without expensive subscriptions or cloud costs. Game developers employ it for rapid prototyping of environments, characters, and assets during pre-production phases. Designers use it as an ideation tool, quickly visualizing concepts before committing to detailed manual work. Educators incorporate it into courses on AI and computer graphics, providing students hands-on experience with modern generative models. Researchers use it as a baseline for studying image generation, or as a component in larger systems combining multiple AI capabilities. E-commerce platforms generate product visualization and lifestyle imagery. Publishers create illustrations for articles, books, and digital content. Architects and interior designers visualize spaces and design concepts. The bilingual capability particularly benefits international teams and projects targeting multiple markets. Small businesses gain access to custom imagery without hiring photographers or graphic designers for every need. Hobbyists and artists explore creative opportunities, using the model as a collaborative tool that responds to their textual descriptions. The low barrier to entry encourages experimentation and innovation across these diverse domains.
Getting Started with Z-Image Turbo
Beginning with Z-Image Turbo is straightforward for users with basic Python and machine learning familiarity. The model is available through multiple channels: direct download from Hugging Face, ModelScope for Chinese users, and GitHub for the complete codebase. Installation involves setting up a Python environment, installing dependencies (primarily PyTorch and Diffusers), and downloading the model weights. The documentation provides clear step-by-step instructions for different platforms and configurations. For users preferring not to manage local installations, the online demo offers immediate access to test the model's capabilities. The demo interface allows prompt input in either English or Chinese, with adjustable parameters for controlling generation characteristics. Code examples demonstrate common usage patterns: basic text-to-image generation, batch processing, parameter adjustment for different styles, and integration with existing pipelines. The repository includes sample prompts showcasing the model's range, from photorealistic portraits to imaginative scenes. For developers, API documentation details the model interface, input formats, output specifications, and configuration options. Community resources include discussion forums, example galleries, and contributed tools extending the model's functionality. Regular updates address issues, improve performance, and expand capabilities based on user feedback.
Model Variants and Extended Capabilities
The Z-Image family extends beyond the base Turbo model to address specialized needs. Z-Image Edit, a continued-training variant, focuses on image editing tasks rather than generation from scratch. This model excels at following instructions to modify existing images—adjusting colors, changing objects, altering styles, or making precise local edits. The editing model maintains consistency with the original image while applying requested changes, a challenging task requiring different capabilities than pure generation. Both models share the efficient architecture philosophy, running on similar hardware requirements. The development team continues exploring additional variants for specific domains or capabilities. The modular design allows researchers to build upon the foundation, creating specialized versions for particular industries or applications. The open-source nature encourages such extensions, with the community already developing tools for specific workflows, custom interfaces, and integration with other creative software. This ecosystem approach means Z-Image Turbo serves as a foundation for a growing collection of image generation and editing capabilities, all maintaining the core principles of efficiency and accessibility.
Community and Future Development
The Z-Image project benefits from active community engagement and ongoing development. The GitHub repository serves as a hub for collaboration, with users reporting issues, suggesting improvements, and contributing code. The development team regularly releases updates addressing bugs, improving performance, and adding features based on community feedback. Discussion forums and social media channels facilitate knowledge sharing, with users posting examples, sharing techniques, and helping newcomers. The project's open nature encourages academic research, with several papers already building upon or analyzing Z-Image Turbo. Future development directions include further efficiency improvements, expanded language support, enhanced control mechanisms for generation, and better integration with creative workflows. The team is exploring techniques to reduce hardware requirements even further, making the model accessible on more modest systems. Research into faster inference methods could reduce the already-quick 8-step process. Improved prompt understanding could make the model more intuitive for non-technical users. The long-term vision is establishing Z-Image as a foundation for accessible, efficient, high-quality image generation—proving that open, community-driven development can produce results matching or exceeding closed commercial systems.
Frequently Asked Questions
Find answers to common questions about Z-Image Turbo's capabilities, requirements, and usage.
What is Z-Image Turbo and who developed it?
Z-Image Turbo is a 6-billion-parameter diffusion model for text-to-image generation, developed by Alibaba's Tongyi-MAI research team. It represents a distilled, optimized version of the larger Z-Image model, specifically designed to deliver high-quality photorealistic image generation with minimal computational requirements. The model uses a single-stream diffusion transformer architecture and can generate images in just 8 steps while maintaining quality comparable to much larger models.
What hardware specifications are needed to run Z-Image Turbo?
Z-Image Turbo is designed to run on consumer-grade hardware, requiring less than 16GB of VRAM. This means it can operate on graphics cards like the NVIDIA RTX 3090, RTX 4080, or similar consumer GPUs. The model's efficient architecture allows it to run on systems that many developers and creators already own, eliminating the need for expensive enterprise hardware or cloud computing costs for basic usage.
How fast is image generation with Z-Image Turbo?
Z-Image Turbo generates high-quality images in just 8 inference steps, significantly faster than traditional diffusion models that typically require 50 or more steps. On consumer-grade GPUs, this translates to generation times of just a few seconds per image. This speed enables rapid iteration and experimentation, making it practical for interactive applications and workflows requiring quick turnaround times.
Does Z-Image Turbo support languages other than English?
Yes, Z-Image Turbo has native bilingual support for both English and Chinese. The model can understand prompts in either language and accurately render text in both scripts within generated images. This bilingual capability extends beyond simple translation—the model understands cultural contexts and aesthetic conventions associated with both languages, making it particularly valuable for international projects and multilingual content creation.
Is Z-Image Turbo available as open source?
Yes, Z-Image Turbo is fully open source under the Apache-2.0 license. The model weights, code, and documentation are publicly available through GitHub, Hugging Face, and ModelScope. The project includes an online demo for immediate testing, comprehensive documentation for implementation, and example code demonstrating common use cases. This open approach encourages community exploration, research, and integration into various applications.
How does Z-Image Turbo achieve quality comparable to larger models?
Z-Image Turbo achieves its impressive quality through several technical innovations: a carefully optimized single-stream diffusion transformer architecture, advanced training techniques including multi-stage pretraining and distillation from larger teacher models, efficient attention mechanisms that focus computational resources effectively, and a refined denoising process that maximizes quality at reduced step counts. These engineering decisions allow the 6-billion-parameter model to match the output quality of models with 60+ billion parameters.
What are the licensing terms for commercial use?
Z-Image Turbo is released under the Apache-2.0 license, which is permissive and allows commercial use. However, users should review the complete license terms and any additional documentation provided with the model to understand specific conditions and requirements. The open license is designed to encourage broad adoption across research, educational, and commercial applications while maintaining appropriate attribution and legal clarity.
What is the difference between Z-Image Turbo and Z-Image Edit?
Z-Image Turbo is optimized for generating images from text prompts, creating new images based on textual descriptions. Z-Image Edit is a specialized variant trained specifically for image editing tasks—it takes an existing image and modifies it according to textual instructions. Z-Image Edit excels at tasks ranging from precise local modifications (changing specific objects or colors) to global transformations (applying different artistic styles). Both models share the efficient architecture philosophy and similar hardware requirements, but serve different use cases in the creative workflow.
Can I fine-tune Z-Image Turbo for specific domains or styles?
Yes, the open-source nature of Z-Image Turbo allows for fine-tuning on custom datasets to specialize the model for particular domains, styles, or applications. The architecture supports transfer learning approaches where the pretrained model serves as a foundation, with additional training on domain-specific data to enhance performance for particular use cases. The documentation and community resources provide guidance on fine-tuning techniques, and the efficient model size makes this process more accessible than fine-tuning larger models.
How does Z-Image Turbo handle complex prompts with multiple elements?
Z-Image Turbo demonstrates strong capability in understanding and rendering complex prompts involving multiple subjects, specific attributes, spatial relationships, lighting conditions, and stylistic directions. The model's text encoder and attention mechanisms are designed to parse detailed descriptions and maintain coherence across multiple specified elements. The bilingual training enhances this capability by exposing the model to diverse ways of describing scenes and objects across different linguistic and cultural contexts.
What image resolutions and aspect ratios does Z-Image Turbo support?
Z-Image Turbo supports various resolutions and aspect ratios, making it flexible for different output requirements. The model can generate images at different sizes without requiring retraining, though performance characteristics and memory usage will vary with resolution. The documentation provides guidance on optimal settings for different use cases, balancing quality, speed, and resource consumption based on specific needs.
How can I get help or contribute to the Z-Image project?
The Z-Image community is active across multiple channels. The GitHub repository is the primary hub for technical issues, feature requests, and code contributions. Discussion forums and social media channels provide spaces for questions, sharing examples, and community interaction. The documentation includes contribution guidelines for those interested in improving the codebase, adding features, or fixing bugs. The development team monitors these channels and regularly engages with the community, incorporating feedback into ongoing development.
What Users Are Saying About Z-Image Turbo
Discover how creators, researchers, and developers are using Z-Image Turbo to bring their ideas to life with efficient, high-quality image generation.
Z-Image Turbo has transformed my workflow. The speed and quality are incredible, and being able to run it on my own hardware means I can iterate quickly without worrying about cloud costs.

Sarah Chen
Digital Artist
The efficiency of Z-Image Turbo is remarkable. We're using it for research on efficient generative models, and the bilingual capabilities make it perfect for our international collaboration.
Michael Rodriguez
AI Researcher
As a solo creator, I need tools that are both powerful and affordable. Z-Image Turbo delivers professional results without requiring expensive hardware. The 8-step generation is impressively fast.
Emily Thompson
Content Creator
We integrated Z-Image Turbo into our product, and our users love it. The model's efficiency means we can offer image generation features without breaking our budget on compute costs.
David Kim
Startup Founder

Ready to Start Creating with Z-Image Turbo?
Experience efficient, high-quality image generation with Z-Image Turbo. Start creating photorealistic images today with our open-source model.
Try Demo Now